RBF Batching at CardCoins: Diving into the Mempool’s Dark Reorg Forest
Because CardCoins interacts heavily with the mempool, we consider both the cost and expected confirmation time of a transaction before it is broadcast. Like other service providers in the Bitcoin ecosystem, we want to minimize our costs while ensuring transactions confirm as quickly as possible.
Service providers have available to them a few different approaches to this problem, the selection of which depends on the nature of the service and the volume of transactions they broadcast to the network. Large exchanges, for example, rely heavily on traditional transaction batching, whereby customer withdrawals are aggregated into a single transaction and broadcast at some interval (e.g. once per hour). Some providers may not have the luxury of waiting for such an interval as their customers expect an immediate payout visible in the mempool. In this case, two strategies can be combined: Replace-by-Fee (RBF, BIP125) and batching.
BIP125 is a signaling method by which a transaction can indicate a certain optionality: that is, given certain constraints, the transaction may be replaced by a subsequent transaction that pays a higher fee. BIP125 places no restrictions on changing outputs when replacing a transaction–thus it is possible to construct replacement transactions that include subsequent customer payouts. There are a few different monikers for this approach, one of which is “additive batching.” CardCoins has small order sizes (<= $500) and guarantees its customers a fast payout transaction–this combination qualifies us as a perfect candidate for such a scheme.
In constructing our RBF batching strategy, we had to account for a number of complexities, some of which could lead to dangerous scenarios, including double payouts to customers, overpaid fees, and payout transactions being pinned at low fees. We’ve outlined these complexities below, as well as how we address these problems.
-
It is possible, given blockchain reorganizations, differing RBF policies amongst miners, poor propagation, network partitions, and mempool evictions that the most recently broadcast batched transaction is not the transaction that confirms.
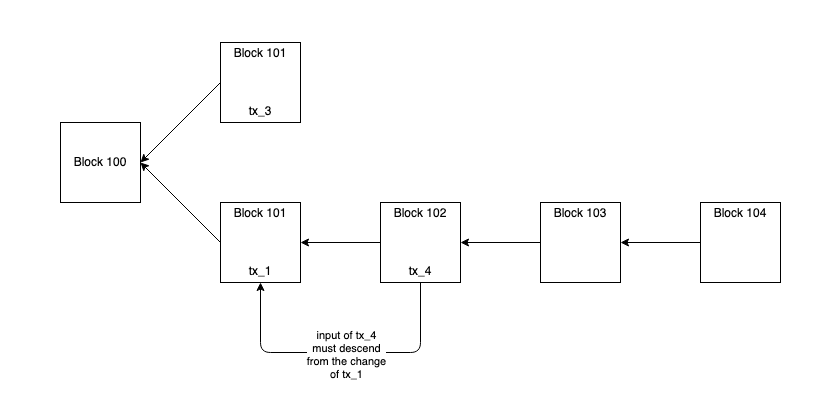
- For example, you have tx_1, which is replaced by tx_2, which is replaced by tx_3. For whatever reason, tx_1 is confirmed and the payouts to customers included only in tx_2 and tx_3 fall off the network. A new transaction must be broadcast for customers whose payout was lost. In a slightly different case, tx_3 may be confirmed, but a later reorganization may cause tx_3 to be made stale, and tx_1 to be ultimately confirmed. A service provider must proactively monitor for these circumstances. Internally, CardCoins has a batch-tracking pool which monitors the state of our active and most recently confirmed transactions.1 When a new block is confirmed, we check for any state changes. In the event that a prior iteration of a batch has confirmed, our batch-orchestration engine prepares the now-orphaned payouts for rebroadcast. While we don’t remove a confirmed transaction from our tracking pool until it has reached 6 confirmations, we do attempt an immediate re-broadcast of the orphaned payouts. This exposes us to a double payout scenario which we describe and mitigate below.

- In the case where tx_1 got confirmed, the payments added in tx_2 and tx_3 must be reissued in a new transaction, tx_4. If tx_4 uses a new independent input that does not descend from the change in tx_1, a blockchain reorganization may repeal tx_1 but confirm both tx_3 and tx_4 which would cause double payout of some customers. To prevent this, it is vital to anchor customer payouts to specific inputs. Our batch-tracking pool notes this input/payout relationship and the batch-orchestration engine enforces descendancy safety when constructing batches from payouts that were made stale.
- For example, you have tx_1, which is replaced by tx_2, which is replaced by tx_3. For whatever reason, tx_1 is confirmed and the payouts to customers included only in tx_2 and tx_3 fall off the network. A new transaction must be broadcast for customers whose payout was lost. In a slightly different case, tx_3 may be confirmed, but a later reorganization may cause tx_3 to be made stale, and tx_1 to be ultimately confirmed. A service provider must proactively monitor for these circumstances. Internally, CardCoins has a batch-tracking pool which monitors the state of our active and most recently confirmed transactions.1 When a new block is confirmed, we check for any state changes. In the event that a prior iteration of a batch has confirmed, our batch-orchestration engine prepares the now-orphaned payouts for rebroadcast. While we don’t remove a confirmed transaction from our tracking pool until it has reached 6 confirmations, we do attempt an immediate re-broadcast of the orphaned payouts. This exposes us to a double payout scenario which we describe and mitigate below.
A service provider must also decide whether or not they want to introduce new payouts into a batch that a customer has spent from. To replace a transaction with descendants, the feerate of the replacement transaction will need to take into account the descendent transaction as well as the customer’s experience–if the customer (or their payee) has already spent the payout, the service provider would invalidate the customer’s transaction by replacing the transaction that created the input. To handle this case, a service provider may for example state explicitly to the customer that they should not spend from the transaction while it is unconfirmed otherwise they risk the transaction being dropped.
We must also consider the risk of a malicious actor DoS'ing a low fee paying RBF batch by way of RBF Pinning, either by creating too-many (>24) or too-large (>100,000 vbytes) descendant transactions. At CardCoins, batches are started with feerates that will see them confirmed in a reasonable amount of time. This mitigates the pinning danger (barring a sudden influx of transactions or slow blocks).
Notably, BIP125 has an anti-DoS provision that requires the replacement transaction to “pay for the bandwidth” of the original transaction. This means that feerates must be selected carefully for the sequence of transaction replacements, otherwise the provider may end up paying more for the replacements than individual transactions for each customer. Specifically, a provider must weigh their preferred confirmation target against the expected number of payouts within that time frame. As each payout is requested, they should bump the fee within the appropriate constraints, which will allow them to reach their target feerate by the final batch while achieving the desired customer experience. This means underbidding the feerate of the first transaction and working their way up towards the desired feerate with each additional RBF batch-up. It also means that if the fees in the mempool are low enough, or if the mempool clears out in between batch-ups, RBF batching may not be cost-effective. To prevent overpaying, the CardCoins batch-orchestration engine checks the current (and expected) feerate of the batch against prevailing fees in the mempool and may opt to start a new batch in lieu of bumping one of the currently active batches.
There is also the consideration of customer wallet software and its support for RBF. Many wallets do not properly handle RBF transactions and show the user suspicious or confusing errors. In the short term, managing this issue is a customer service problem–the service provider should have clear messaging around their RBF batching scheme to educate their users. In the long term, we hope wallets will improve their own communication about the state of RBF transactions.
We have learned a lot in this journey–writing this software has certainly been a challenge, dealing with the cases described above as well as other complexities which are specific to the ways in which we manage our hot wallets.
That said, we have had some success in the last eight months as we have begun rolling this feature out to our vendors (who don’t yet support lightning) and select beta customers. We’ve had a lot of fun building our batch-orchestration engine/batch-tracking pool and we hope the lessons we have learned will help other service providers make informed decisions when selecting strategies to reduce their fees and on-chain footprint, all while remaining safe from the many dangers posed by manipulating unconfirmed transactions in the dark reorg forest.
Special thanks to Matthew Zipkin for aiding us in the implementation of this scheme. Additional gratitude to those who helped review this post including David Harding, John Newbery, Mike Schmidt, Antoine Riard, and Murch.
1 Our batch-tracking pool stores an array of customer-requested payments. Every time a new payment is requested, the array is scanned and compared against mempool and block data from Bitcoin Core. For each payment, we maintain a sub-array of txids that attempted to fulfill that payment. Payments with 6 confirmations are removed. Payments that are still unconfirmed may be included in a batch with the next payment request. When batches get too big, a new batch is started by a single payment, then the next payment can be batched with that payment, and so forth. If there are multiple batches in the mempool, the system always tries to add new payments to the smallest batch.